Deploying instances in the cloud is something that is relatively fast - at least when it comes to the deployment of a Linux instance.
Windows Operating Systems - is a whole different story.
Have you ever thought why it takes such a long amount of time to deploy a Windows instance in the cloud? There are a number of reasons why this takes so much longer.
Let me count the ways:
- Running Windows in the cloud - is a dumb idea - so you deserve it!! (just kidding :) )
- Seriously though - Windows images are big - absolutely massive compared to a Linux image - we are talking 30 times larger (on the best of days) so copying these large images to the hypervisor nodes takes time.
- They are slow to start.. Windows is not a thin operating system - so it takes time.
I started to look into the start time of Windows (for a whole different reason) and found something really interesting.
This is not documented anywhere - and I doubt I will receive any confirmation from AWS on the points in this post - but I am pretty confident that is the way this works.
It seems that there is a standby pool of Windows instances that are just waiting in the background to be allocated to a customer - based on customer demand.
Let that sink in for second, this means there is a powered-off Windows instance - somewhere in the AZ waiting for you.
When you request a new Windows EC2 instance, an instance is taken from the pool and allocated to you. This is some of the magic sauce that AWS does in the background.
This information is not documented anywhere - I have only found a single reference to this behavior on one of the AWS forums - Slow Launch on Windows Instances

I did some digging of my own and went through the logs of a deployed Windows instance and this provided me with a solid picture of how this actually works. This is what I have discovered about the process (with the logs to back it up).
The date that this was provisioned was the 17th of March.
- On the 17th I launched a Windows instance in my account at 13:46:41 through the EC2 console.

- You can see that AWS does not make the instance available for about 4 minutes - until then you cannot login
(have you ever wondered why?? - hint, hint carry on reading.. )
- After waiting for just under 4 minutes I logged into the instance and from the Windows event log - you will see that the first entry in the System log is from February 13th at 06:52 (more than a month before I even requested an instance).
This is the day that the AMI was released.
- At 06:53 that same day the instance was generalized and shutdown


- The next entry in the log was at 04:55 on the 17th of March - which was just under
8 hours before I even started my EC2 instance!!
- The hostname was changed at 04:56

- And then restarted at 04:57

- After the instance came back up - it was shutdown once more and returned to the pool at 04:59.


- The instance was powered on again (from the pool) at 11:47:11 (30 seconds after my request)

More about what this whole process entails further on down the post. - The secret-sauce service then changes the ownership on the instance - and does some magic to manipulate the metadata on the instance - to allow the user to decrypt the credentials with their unique key and allow them to log in.

- The user now has access to their instance.
I wanted to go a bit more into the entity that I named the "Instance Pool". Here I assume that there is a whole process in the background that does the following (and where the secret sauce really lies).
This is is how I would assume how the flow would be:
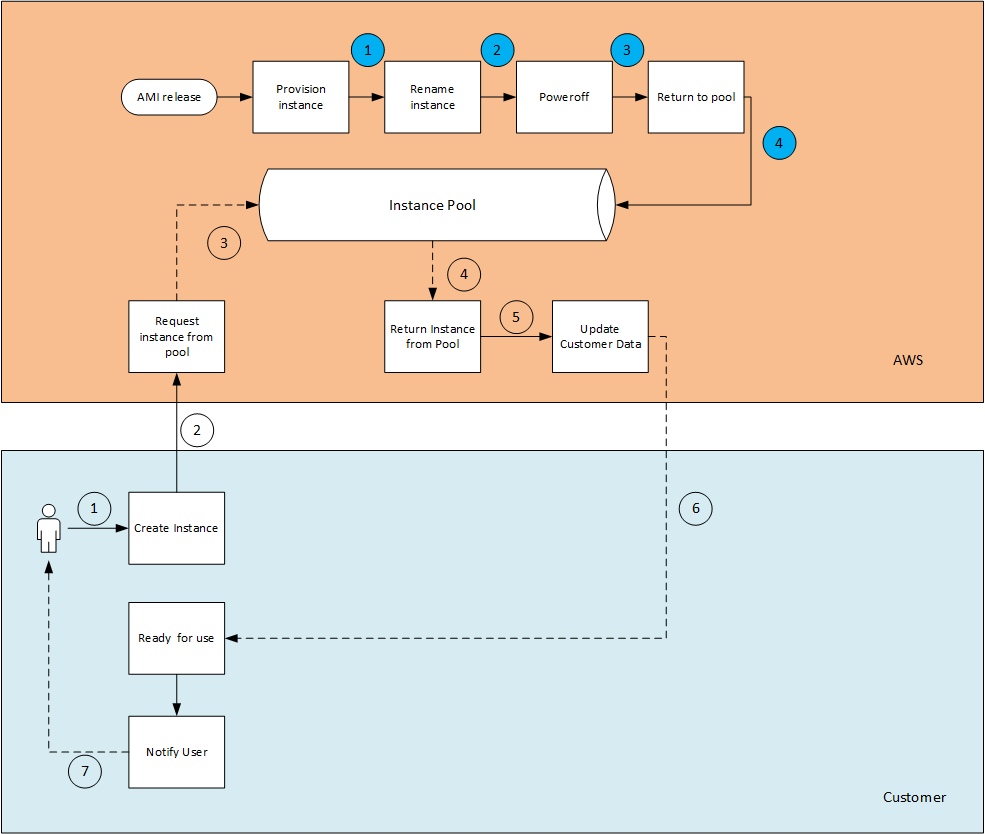
There are two different entities here at work - one is the AWS backbone service (in orange) and the User/Customer (in blue). Both of the sequences work in parallel and also independent of each other.
- AWS pre-warm a number of Windows instances in what I named the "Instance pool". They preemptively spin up instances in the background based on their predictions and the usage patterns in each region. I assume that these instances are constantly spun up and down on a regular basis - many times a day.
- A notification is received that a customer requested an instance from a specific AMI (in a specific region, in a specific AZ and from a specific instance type - because all of these have to match the customers request).
- The request is matched to an instance that is in the pool (by AMI, region, AZ, instance type)
- The instance is then powered on (with the correct modifications of the instance flavor - and disk configuration)
- The backend then goes and makes the necessary modifications
- ENI allocation (correct subnet + VPC)
- Account association for the instance
- Private key allocation
- User-data script (if supplied)
- Password rotation
- etc.. etc..
This also makes perfect sense that when you deploy a custom Windows AMI - this process will not work anymore, because this is a custom AMI and therefore the provisioning time is significantly longer.
And all of this is done why?
To allow you to shave off a number of minutes / seconds wait time to get access to your Windows instance. This is what it means to provide an exceptional service to you the customer and make sure that the experience you have is the best one possible.
I started to think - could this possibly be the way that AWS provisions Linux instances as well?
Based on how I understand the cloud and how Linux works (and some digging in the instance logs) - this is not needed, because the image sizes are much smaller and bootup times are a lot shorter as well, so it seems to me that this "Instance Pool" is only used for Windows Operating systems, and only for AMI's that are owned by AWS.
Amazing what you can find from some digging - isn't it?
Please feel free to share this post and share your feedback on Twitter - @maishsk