I called it - to me it was obvious that this was going to happen. The signs were all there. This was the direction that the market has been pushing for, and AWS has a reputation of giving the customers what they ask for.
The last announcement that was Andy Jassey made on the keynote on Wednesday - was AWS Outposts.
Here was the announcement. Usually Jeff Barr (or as of late - someone else on the Technical Evangelist team) have a detailed blog post - on a new product that was just announced.
For AWS Outposts - nada… The only thing that is out there - is the announcement - and a “TBD” product page - https://aws.amazon.com/outposts/

Once the announcement was made - VMware went all out with as much information as they could describing the VMware variant of AWS outposts https://cloud.vmware.com/community/2018/11/28/vmware-cloud-aws-outposts-cloud-managed-sddc-data-center/
Blog posts, interviews, sessions you name it they went all in - for a very good reason - if you ask me. This expands their VMware Cloud on AWS in a substantial way.
And who was missing from this announcement ? AWS.
To me this is puzzling. The one sided coverage of something that is supposed to be a joint venture, means that either - this was a pure publicity announcement - and the product has not yet been finalized - or AWS dropped the ball on this one - big time!!
So what do we know about a this product? It will come in two flavors:
VMware Cloud on AWS Outposts allows you to use the same VMware control plane and APIs you use to run your infrastructure
A native variant of AWS Outposts allows you to use the same exact APIs and control plane you use to run in the AWS cloud, but on-premises.
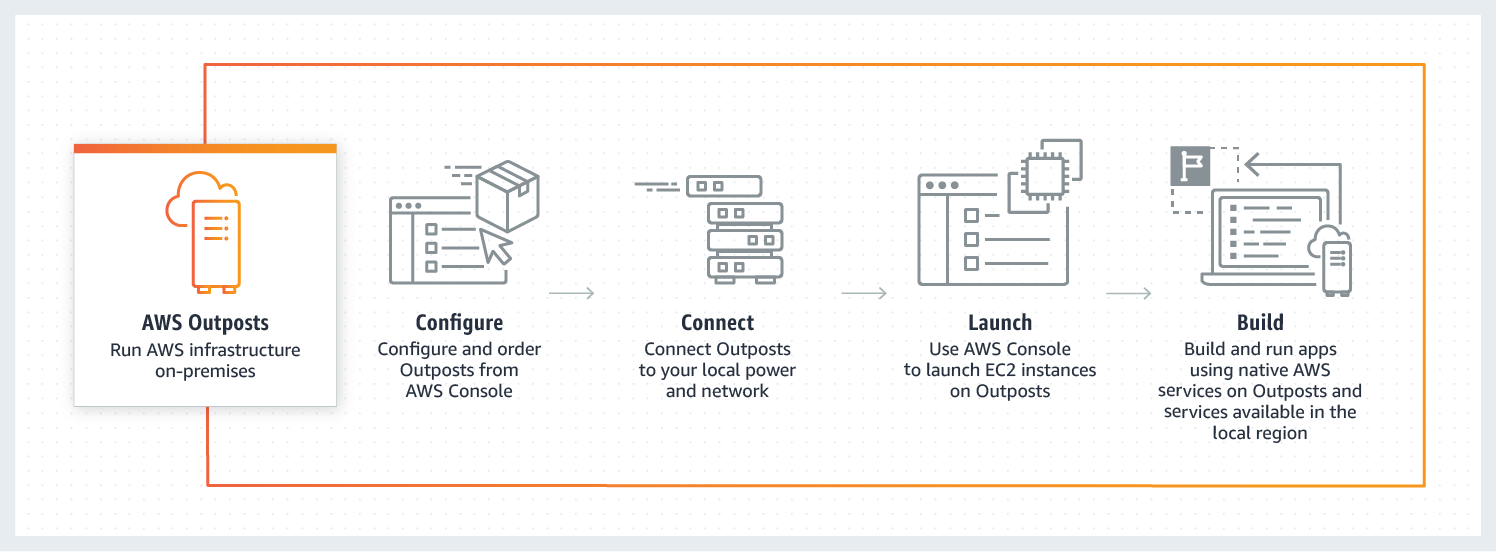
The AWS native variant of AWS Outposts allows you to use the same exact APIs and control plane you use in the AWS cloud, but on-premises. You will be able to run Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Elastic Block Store (Amazon EBS) on Outposts. At launch or in the months after, we plan to add services like RDS, ECS, EKS, SageMaker, EMR.
Not a word has been published since the announcement, of how this is going to work from the perspective of the “AWS variant” Outposts.
I even went as far and asked Jeff Barr - what is the story here. The funny thing is - I actually met him at Starbucks about 15 minutes after I posted the tweet.
His answer (if my memory serves me correctly) was..
“The team had not yet had the opportunity to go into detail into the new offering, and would be publishing more details about it"
To me Outposts - is the biggest announcement of the whole of re:Invent - if played correctly - it will remove any and all competition that is hoping to provide a Hybrid cloud story - one that enterprises can understand.
You want AWS - you can have it - in the cloud - and also on prem - the same exact experience - this is something that customers have been asking for years for AWS to provide (and also something that AWS have consistently been completely against - because everything and anything should run in AWS - there is no need for on-prem… - until now :) )
And mark my words, once you have an Outpost in almost every single datacenter - the need for Edge locations in each and every country - will be no more...
I guess we will have to wait for the aftermath to die down - and wait to see exactly how this going to work….
And now some of my personal thoughts about this whole topic.
There are a lot of moving parts that AWS will now have to go into - especially regarding the logistics of providing the end service to the customer.
If you remember there was once another product - that provided you with a similar service - yep I am talking about the vBlock - a joint venture from VMware, Cisco and EMC. Which went the way of the dodo. The partnership fell apart for a number of reasons.
Customers loved the solution!! You had a single number to call - for anything and everything related to the deployment. Disk died? Called the support number. Network not working? Call the support number. vSphere doing some crazy shit? Call the same support number. One neck to throttle, and customers loved it.
And now you have Amazon selling you hardware - or should I rather say leasing you the hardware. You will not own it - you will pay as you go. I assume that there will be a commitment - of some kind - and you will not be able to order by the hour - the logistics on per hour would be too complicated.
But speaking of logistics - if there is a company that commit to having a 4 hour delivery time on a failed piece of hardware - it is Amazon - with their global presence. They have the logistical capability to ensure delivery of practically anything in their inventory to anywhere in the world - in the shortest amount of time.
But there are still many unknowns... here are a few that come to mind:
- Will this come with a networking component? I assume it will - what will that network component be? Software? Hardware?
- By providing you (the customer) with the same experience and AWS hardware - are they risking exposure of how AWS works getting out? I assume that this will be covered in TOS and NDA that you sign as part of the upcoming service.
- I assume there will be redundant network connectivity requirements in order for this to work - I will also go out on a limb and say that a Direct Connect link will be a requirement as well. This means that it will be only be suitable for a certain piece of AWS's customers. Perhaps redundant VPN's might be suitable as well.
- What happens if/when the AWS endpoints are not available? How if at all can the instances and the workloads on the Outpost be managed?
- How self-service will the offering be? I assume it will only be a node-by-node expansion - or per 1/4 rack. you will not be able to add more disks on your own, more RAM on your own etc. This makes sense.
In short - since this was announced at re:Invent 10 days ago - and that AWS have already stated this will not be available before H2 2019 - I do not expect that we will see anything before October/November 2019 (but that is just my hunch).
At the moment - there is a lot more to this announcement than meets the eye....





















![[UNSET]](https://maishsk.com/blog/images/Abusing-DevOps_8C42/UNSET.png "[UNSET]")















