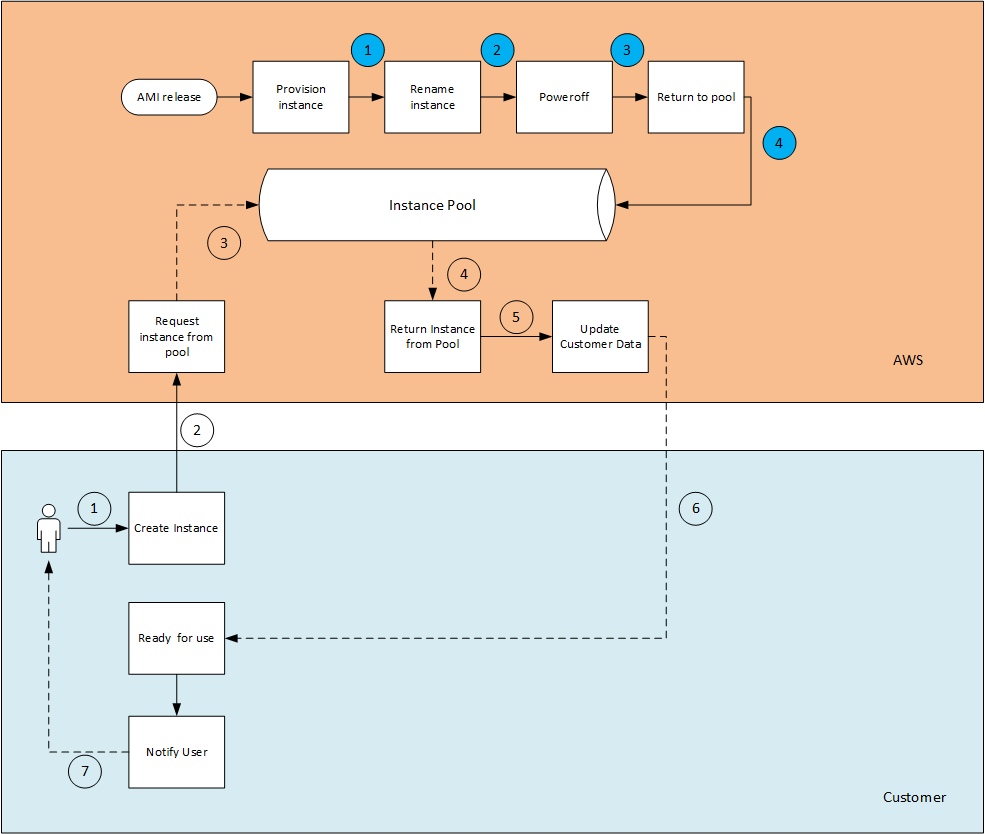
I have come across this a number of times of the past couple of months. Environments that were born in the datacenter, have grown in the datacenter - in short people who are used to certain (shall we say - ‘legacy’) deployments, and they they are in the midst of an attempt to mirror the same architecture when moving to the cloud.
I remember in my old days that our server farm had a separate network segment (sometimes even more than one) when I was using physical servers, (while I write this - I actually think it has been about 4 years since I actually touched a physical server, or plugged a cable/disk/device into a physical server) for our Domain controllers, Applications servers, and users had their own network segments that were dedicated only to laptops and desktops.
In the physical/on-prem world - this made sense - at the time - because what usually happened was the dedicated networking team that managed your infrastructure used access lists on the physical network switches to control which networks could go where.
Fast forward to the cloud.
There are people which equate VPC’s with Networks (even though it makes more sense to equate subnets to networks - but that is besides the point) - and think that segregating different kinds of workloads into multiple VPC’s will give you better security.
Let me give you a real scenario that I was presented with not too long ago (details of course have been changed to protect the innocent … )
A three tier application. Database, Application and a frontend. And the requirement that was laid down from the security team was that each of the layers must reside in the their own VPC. Think about that for a minute. Three VPC’s that would be peered to ensure connectivity between them (because of course the 2/3 layers needed to communicate with each other - Database - application and application to frontend). When I asked what was the reason for separating the three different layers in that way, the answer was, “Security. If for example one of the layer was compromised - it would be much harder to make a lateral move to another VPC and compromise the rest.”
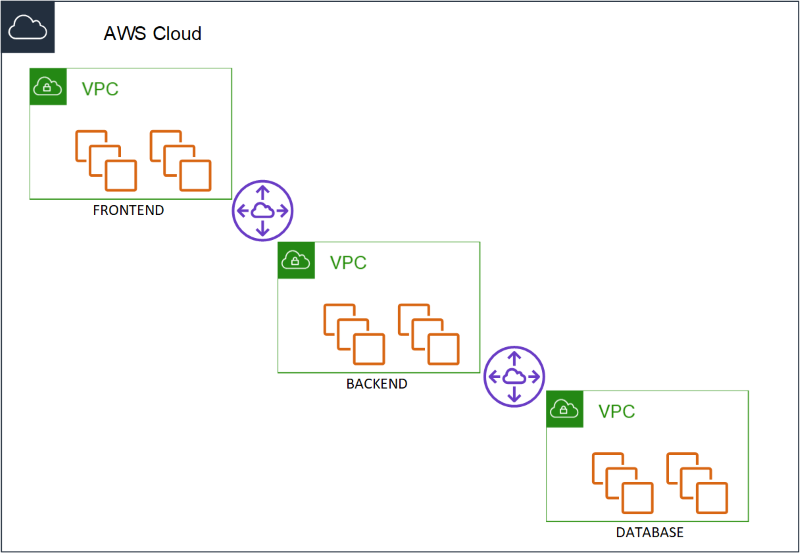
So what is lateral movement? I know that there is no such a thing as a 100% secure environment. There will always be hackers, there will always be ways around any counter measures we try and put in place, and we can only protect against what we know and not against what we do not. The concept of lateral movement is one, of compromising a credential on one system and with that credential moving to another system. For example - compromising a Domain admin credential on an employees laptop - and with that credential moving into an elevated system (for example a domain controller) and compromising the system even further.
So how would this work out in the scenario above. If someone would compromise the frontend - the only thing they would be able to connect to would be the application layer - the frontend - does not have any direct interaction with the database layer at all, do your data would be safe. There would be a peering connection between the Frontend VPC an the Application VPC - with the appropriate routing in place to allow traffic flow between the relevant instances, and another peer between the Application VPC and the Database VPC - with the appropriate routing in place as well.
What they did not understand - is that if the application layer was compromised - then that layer does have direct connectivity with the data layer - and therefore could access all the data.
Segregating the layers into different VPC’s would not really help here.
And honestly - this is a risk that you take - which is why the attack surface you have - exposed on your frontend - should be as small as possible - and secure as possible.
But I came back to the infosec team and told them - what if I would provide the same security and segregation that you were trying to achieve but without the need of separate VPC’s ?
I would create a Single VPC - with three subnets and three security groups, Frontend, Application and Database. Instances in the frontend security group would only be allowed to communicate with the instances in the application security group on a specific port (and vice-versa) and the instances in the application security group would only be allow to communicate with the instances in the database security group (and vice-versa).
The traffic would be locked down to the specific flow of traffic and instances would not be able to communicate out of their security boundary.
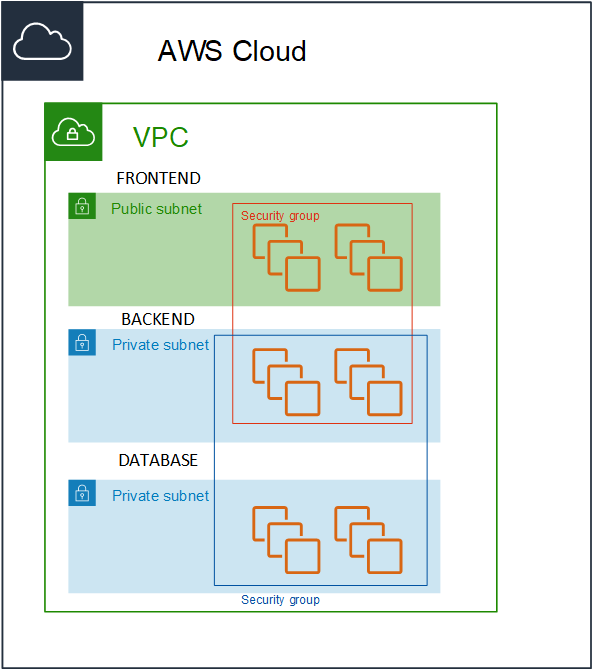
As a side note - this could have also been accomplished by configuring very specific routes between the instances that needed to communicate between the VPC’s, but it does not scale to an environment larger than a handful of instances. Either you need to ensure that the IP addresses in a manual fashion, or keep on adding multiple routes in the route tables.
It goes without saying that if someone managed to compromise the frontend, and somehow managed through the application port to gain control into the application layer - they could gain access (in theory) to the data in the data layer.
Which is exactly what happened in the same scenario with 3 separate VPC’s. No less secure - no more.
But what changed??
The operational overhead of maintaining 3 VPC’s for no specific reason was removed.
This includes:
- VPC Peering (which has a limit)
- Route tables (which has a limit)
- Cost reduction
I could even take this a bit further and say I do not even need different subnets for this purpose - I could actually even put all the instances in a single subnet and use the same mechanism of security groups to lock down the communication. Which is true. And in an ideal world - I probably would have done so - but in this case - it was a bit too revolutionary to already have made the step of going to a single VPC - and to go to a single subnet - was pushing the limit - maybe just a bit too far. Sometimes you need to take small victories and rejoice and not go in for the jugular.
I would opt into option of using separate VPC’s in some cases such as:
- Different owners or accounts where you cannot ensure the security of one of the sides.
- When they are completely different systems - such as a CI system and production instances
- A number of other different scenarios
The bottom line of this post is - traditional datacenter architecture - does not have to be cloned into your cloud. There are cases where it does make sense - but there are cases where you can use cloud-native security measures - which will simplify your deployments immensely and allow you to concentrate as always on the most important thing. Bringing value to your customers - and not investing your time into the management and maintenance of the underlying infrastructure.
Please feel free contact me on Twitter (
@maishsk) if you have any thoughts or comments.